Looking for a post office? How about a 150,000 of them?
by Miklós Koren
In a recent project, we proxy 19th-century local economic development with the number of post offices in the neighborhood. We have downloaded all historical post office names and dates from Jim Forte’s Postal History (with his permission) to create a geospatial database.
How many post offices were there in Kings County, NY, in 1880? In answering this question, we faced a computational challenge: spatially querying 150,000 points is not trivial. The naive algorithm would go through all points and make a spatial comparison with the polygon: “Is this point inside the polygon?” This is clearly an inferior solution. When we asked QGIS to calculate the number of post offices by counties, it hadn’t finished in three hours. Maybe I am impatient, but this seemed unacceptable to me. So I started researching the quadtree algorithm.
The basic idea of a quadtree is that it splits the plane in four quadrants. Much like binary search, this makes searching faster. log(N) fast, to be precise.
Finding points within a polygon is trivial if the bounding box of all points is inside.
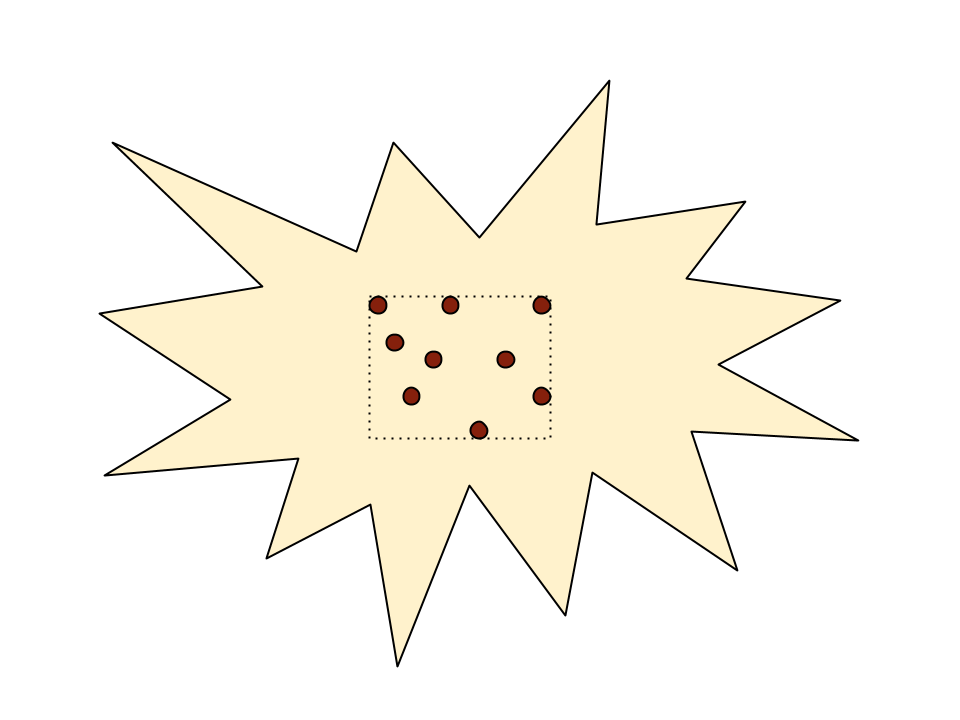
Much less so if some of the points are outside.

However, if the points are stored in a quadtree, we will find that the bottom-right quadrant of rectangle is inside the polygon. And so are the two post offices inside.
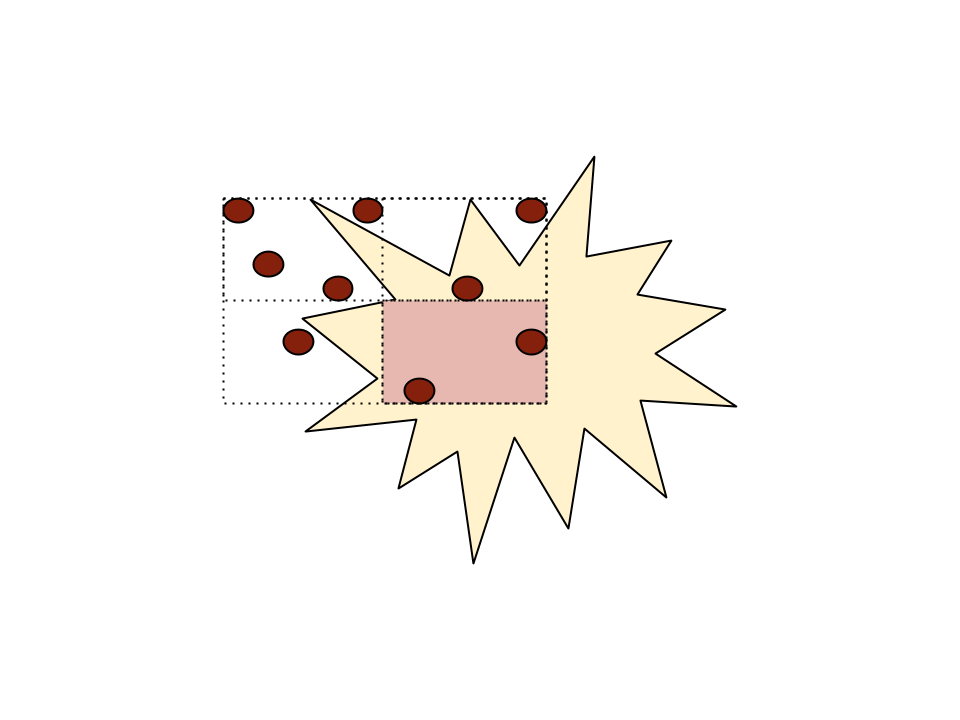
To find the remaining points, we keep splitting the quadrants into further and further quadrants.
I implemented this algorithm in a python module. You instantiate the QuadTree class with a list of points (which may come as pairs of coordinates or as a GeoJSON string), which builds a quadtree with at most 11 points in each quadrant. You can than query this quadtree with any polygon like this:
post_offices = QuadTree([...])
kings_county = Feature(...)
print post_offices.count_overlapping_points(kings_county)
If post offices were equally distributed in space, the quadtree would be at most 7 layers deep. This means drastically fewer spatial comparisons.
As a result, I could count and list post offices in a matter of a seconds instead of a hours.