Which binary classification model is better?
by János K. Divényi
Receiver Operating Characteristic curve
is a great tool to visually illustrate the performance of a binary classifier.
It plots the true positive rate (TPR) or the sensitivity against the false
positive rate (FPR) or 1 - specificity. Usually, the algorithm gives you a
probability (e.g. simple
logistic regresssion),
so for classification you need to choose a cutoff point. The FPR-TPR pairs for
different values of the cutoff gives you the ROC curve. Non-informative
algorithms lie on the 45-degree line, as they classify the same fraction of
positives and negatives as positives, that is TPR = TP/P = FP/N = FPR.
But what if you want to compare two algorithms which give direct classification,
i.e. you have only two points in the plot? How to decide whether algorithm (2)
is better than algorithm (1)?
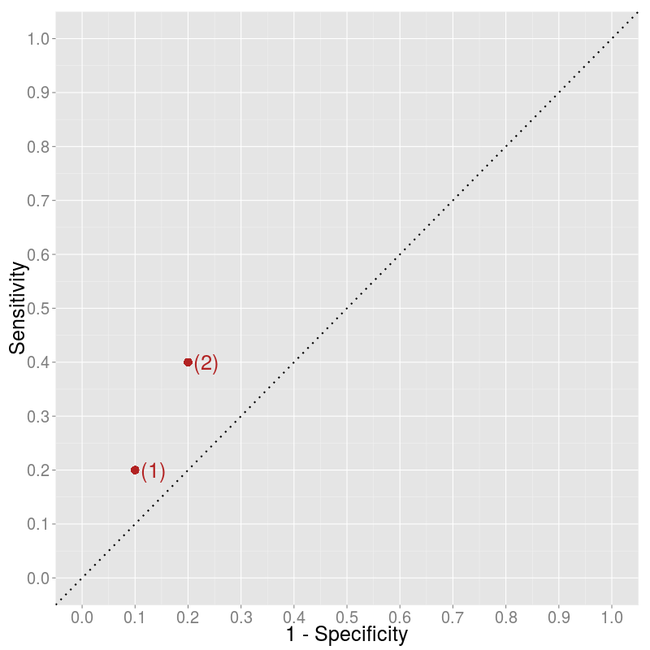
It is clear that algorithm (2) classifies more items as positive...
